



From Startup to Unicorn - Data Quality saves Costs and contributes to Revenue also in Logistics
Fr(AI)ght Perspectives - A gentle entry to Machine Learning for decision makers in logistics

Have you ever heard about NASA's Mars Climate Orbiter? This $300 million spacecraft was lost in 1999. Orbiters got lost all the time. But what has this to do with data quality? The crash resulted from different units being used in the orbiter modules. NASA utilised the metric SI system, while the supplier, Lockheed Martin, used Imperial units. As a consequence velocity and height of the orbiter were determined too low and resulted in $300 million literally evaporating in the Martian sky due to low data quality.
This is not an isolated incident. Many companies lose money due to poor data quality.
Yet, data quality isn't just about preventing loss. It also presents an opportunity. When Google launched in 1998, the search engine market was dominated by heavyweights like Yahoo, Lycos and Alta-Vista. Despite being only a small start-up, Google managed to compete, primarily due to high data quality of their search results. Hence, Google`s success was built on exceptional data quality.
Many processes in logistics companies rely on data, even when it is not always explicitly acknowledged. I am certain that many of you have faced challenges with currency conversions or complications from acquisitions that have screwed up your overall freight cost analysis at least once. I haven't even broached the subject of postal code format and conversion, which frequently leads to operational issues.
Have you ever experienced the failure of transportation costs aggregation at higher levels, like per country or business unit? The reason for these problems usually stems from low data quality, which is costly. After all, how do you want to analyse and optimise your cost structure without detailed information on your transportation costs?
While data-based decisions are beneficial, especially in logistics, low data quality can negatively impact these choices. In the best-case scenario, there is no impact. But more realistically, decisions based on poor quality data are suboptimal, leading to missed profits or worse, losses.
So data quality equates to revenue, particularly for data-driven businesses. The value in data often only becomes apparent when it generates direct revenue. However, this usually requires a certain level of data quality. With this in mind, maintaining high data quality should be a top priority for all companies, as it is an investment in their future.
What are the consequences of poor data quality?
We’ve discussed why data quality is vital from a business perspective. Now, let's explore some instances that highlight the technical implications of poor data quality.
Simple aggregations, like calculating the mean, typically rely on a significant sample size, to average out outliers. Thus, the influence of a small number of outliers on the mean value should be low.

However, when data is scarce, outliers can significantly skew the mean. For this reason, it's crucial to calculate aggregated quantities like the mean based on a large enough sample size. What exactly a ‘large enough sample size’ is, varies with the use case, but generally, larger data-sets yield better results. In many scenarios, it's difficult to simply increase the amount of data, due to limitations in availability or cost. In these cases, ensuring high data quality is paramount. Better data quality generally reduces the sample size requirement.
Why is data quality even more important for Machine Learning?
While we can control the number of samples used for simple aggregations, this control diminishes in Machine Learning. Admittedly, we can still control the number of training samples. However, for many state-of-the-art algorithms like Neural Networks, it is beyond our control how many of these samples are actually consumed. There might be situations where the ML model relies on information based on a few training samples only. If any one of these samples is of poor data quality, the resulting prediction is likely to be inaccurate.
To illustrate how low data quality can confuse a ML model, let's perform a dummy image classification task. The aim is to distinguish between trucks and cars. We train a dummy model on the three images below.

Clearly, the last image is mislabeled. It depicts a dragon, not a truck, and should not be included in the training data. In that context, it represents poor quality data. Although it is obvious to us that the last image doesn't belong in this example, it is hard for a ML model to find out. Consequently, the ML model will attempt to learn the properties of a truck from it.
During training, the ML model learns the properties of the classes ’Truck’ and ‘Car’ and develops a prototypical concept based on them. If we were to translate this prototypical concept into an image, it might look like this:

As humans, we inherently understand that a truck cannot have wings. For a ML model, it's not that simple. An ML model learns from all data, both high and low quality. Consequently, it may learn incorrect properties from low quality data and derive an inaccurate concept of a truck.
To illustrate the impact of poor data quality on a ML model, let's revisit the pricing example from our previous article. Alongside our 10 samples of high-quality data (marked yellow), we introduce three samples of poor quality data (marked green). In this case, the distance was not correctly converted from miles to kilometres, causing the prices to appear disproportionately high for the given distance.
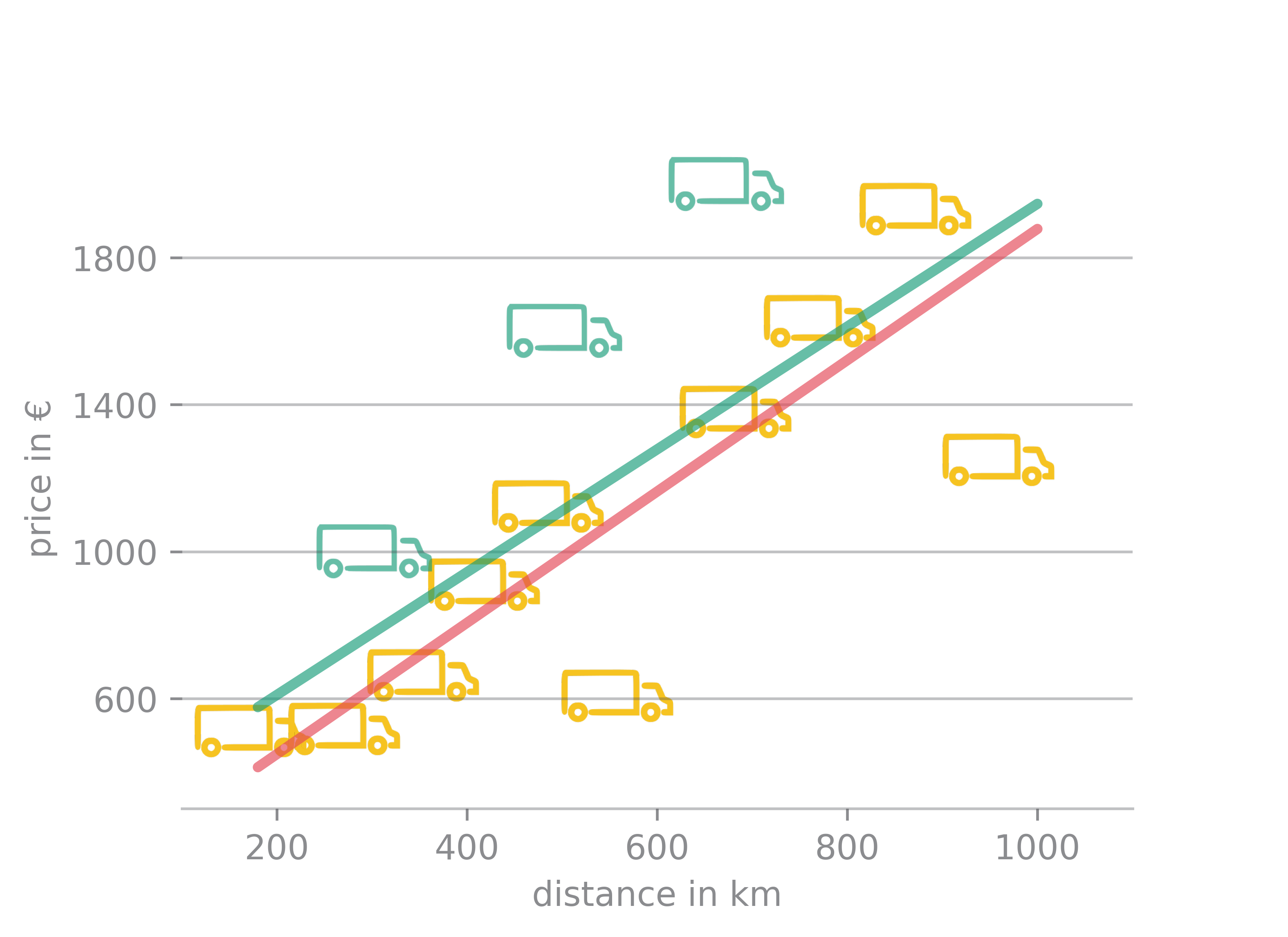
The linear model consumes these low-quality data samples in the same way it does with all the other samples. The result is that the green model, trained on low and high quality data, predicts significantly higher prices than the red model, which was only trained on high quality data.
How to improve Data Quality?
We have seen how low data quality can impact ML models. Now we aim to explore how to improve data quality. While there are countless approaches, we will focus on four that we have found particularly useful.
1 - Define Expectations
Start by defining your expectations for the data. A good starting point is identifying the data types you anticipate. For instance, if you have a form, designate the expected data type for each field. Determine whether you are expecting a timestamp, text or number, and whether it should be integer or float. This information will help you validate your data later on.
Next, limit the possible values in the fields as much as you can. Avoid free text fields whenever possible and set boundaries. For example, a bill of lading with a timestamp from 24 A.D. might be an archaeological sensation, but it is most likely to result from a typo in the millennial integer. Thus, it is often sensible to limit valid timestamps to the most recent one or two years.

2 - Validate the Data
Data validation should ideally be performed at the time of data creation. For instance, if a user enters an unloading date of '1024-07-01' in our form, real-time feedback enables immediate correction. Even if the data cannot be corrected, marking it as unreliable can be beneficial, as it can be excluded from analysis.

3 - Data Standardisation
The Mars Climate Orbiter’s crash underscores the critical importance of standardisation in data quality. The crash resulted from a lack of standardisation in the units used to measure height and velocity. This challenge often appears in logistics as well, where units that are used to measure load size can vary, even within the same company across different locations. Tons, m³ or piece counts are only the most common units used here.
The time-zone is another often underestimated piece of information. When minutes and hours matter, the time-zone must be stored. If no time zone is available, use UTC and store additional information, such as where the timestamp was recorded.
Given the difficulty of establishing a single unit of measurement company-wide, it is beneficial to store other values as well. For instance, if 3 pallets are being loaded, record the weight and volume in addition to the quantity. This enables the comparison and optimization of rates across the company later on.

4 - Documentation
It may seem surprising, but documentation is an essential part of data quality. If the meaning of high-quality data is misunderstood, its value is diminished. Documentation doesn't necessarily have to be extensive manuals. Often, short notes are sufficient. However, it's crucial that these notes are readily accessible with the data. This is one advantage of using databases, as most common databases allow users to store comments alongside the data.

Conclusion
Improving or maintaining high data-quality is usually worth the effort, even if it initially appears costly. There are no shortcuts to achieving high data quality, and while it can be laborious, the long-term benefits outweigh the initial effort.
Higher data quality allows for resource allocation elsewhere and opens up unforeseen opportunities. Today's AI models would not exist without Google’s revolutionary data processing concepts developed in the 90's .
Even without considering future opportunities, consider how much money NASA has saved since the Mars Climate Orbiter crash in 1999 by explicitly checking for unit conversion.
Martin Bastian
Data Scientist
If you have questions or suggestions for new topics that we should cover in this series please reach out to us or comment below.